使用強化學習之動作同步遠端操控人型機器人
此作品為碩士論文,並參與2022年未來科技獎競賽
完整競賽影片 : 2022未來科技獎 (於影片後段有demo影片)
論文摘要
設計一套基於姿態遠端控制機器人系統,操作者配戴感測器對機器人手部姿態重定向與腿部控制,搭配語音系統使人機兩端能進行語音通訊,頭部配戴VR頭戴顯示器以獲取機器人視野,藉此將自己化身為機器人與他人進行互動。
系統架構
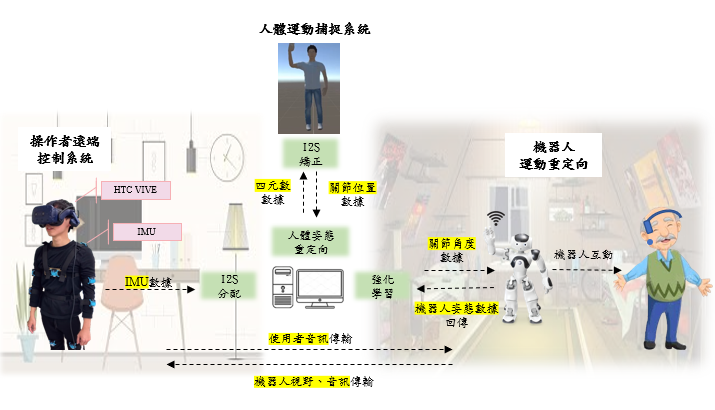
操作者遠程控制系統
本研究操作者端將配戴HTC VIVE VR頭戴式顯示器以獲取機器人視野畫面與機器人頭部轉向控制,透過麥克風與喇叭與機器人端進行對話交流,人體姿態感測系統由14顆姿態感測器所組成。
人體運動捕捉系統
將人體姿態投射於Unity中,收集25個關節之三軸座標位置,並依據Kinect V2所定義之關節點作為本研究關節資料儲存形式。
機器人系統
本研究使用機器人為Nao-V6,全身配有25個自由度,主要分布於頭部、手部與足部。
- 手部控制: 能夠透過強化學習與逆向運動學兩種模式實現。
- 腿部控制: 為考慮機器人安全性,腿部動作使用預設前進、側移、轉向等動作。
- 頭部控制: 透過虛擬實境頭盔控制機器人頭部轉向,與機器人視野追蹤。
- 音訊控制: 建立錄音、播音系統傳輸兩地音訊。
資料傳輸
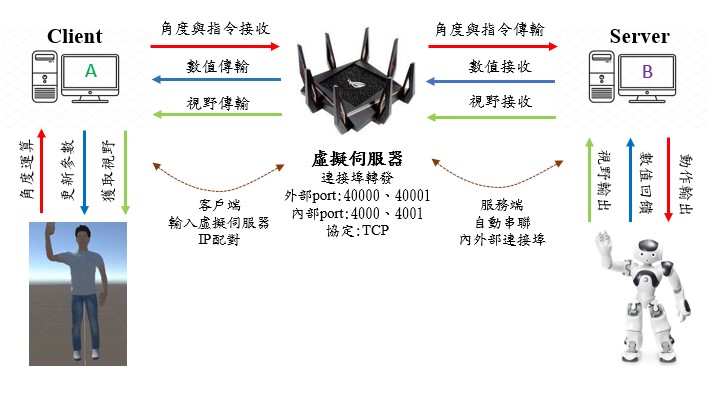
資料傳輸透過Python Socket TCP網路通訊程式實現,在傳輸系統中又分為服務端(Server)與客戶端(Client),給定IP地址、協議方式與連接埠來建立溝通。
本研究以TCP協定進行資料傳輸,由於機器人需與路由器綁定,故於此路由器建立虛擬伺服器,並設置連接埠轉發功能,客戶端與服務端集可跨域傳輸資料。
系統設計
本研究使用 強化學習 與 逆向運動學 兩方式對機器人手臂作運動重定向,分析兩種方法之優劣。
手部控制
資料前處理
Unity與機器人兩座標軸不同,建立方向餘弦(DCM)矩陣,將Unity中的骨骼資訊進行座標轉換至機器人座標軸。

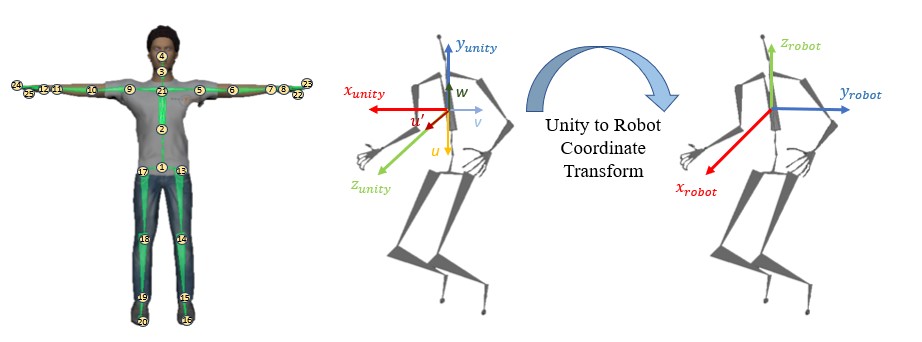
座標軸轉換結果
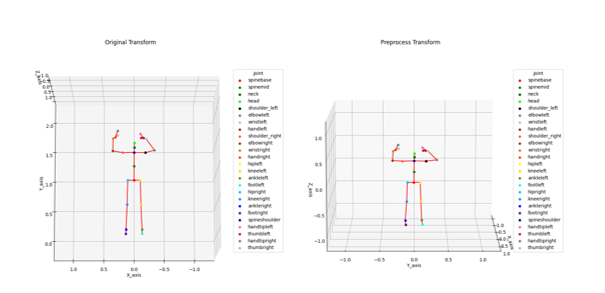
1. 逆向運動學
下圖為機器人左右手臂的鏈結框架。
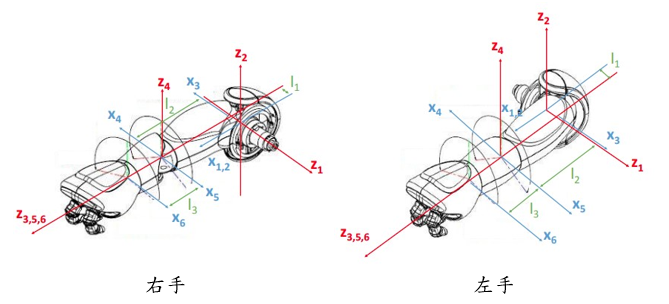
Denavit-Hartenberg參數模型(D-H模型),將每個連桿建構座標系,以便描述當前連桿座標系與相鄰連桿座標系之間的轉換關係,下表為Nao機器人依據鏈結框架所建置之D-H模型。

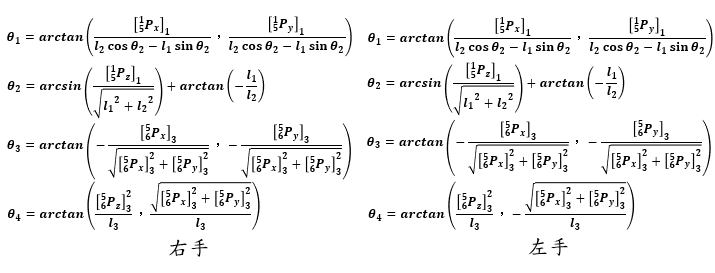
因左右手臂參數模型不同,故左右手臂有不同的逆向運動解。由於機器人與人體維度不同,需將前處理後人體向量映射至機器人向量,代入逆向運動學公式中,即可回推機器人手臂關節旋轉角,以驅動機器人手臂至目標位置,使機器人模仿人體的手部姿態。
2. 強化學習
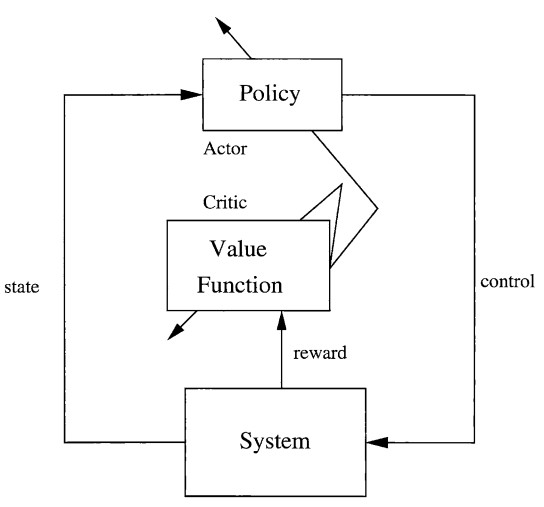
強化學習模型使用行動者評論家網路,為一種結合策略梯度與時序差分(Temporal difference)的強化學習方法,它使用兩個深度學習模型,分別為行動者與評論家。行動者模型學習在特定環境狀態下應該執行什麼動作,當行動者模型選擇的動作被執行後,智能體與評論家模型將從環境中獲得獎勵。評論家模型的作用為優化行動者模型,將行動者模型依據前狀態採取之動作給予評級,而智能體將基於評級比較當前策略與新策略,並決定如何改進行動者模型以採取更好的行動。
給定6個目標動作,分別為歡呼、揮手、指向、擦臉、敬禮、雙手合十,這些動作是人與人之間常有的互動動作。機器人端預先設計好這6類動作,而受試者端透過人體運動捕捉系統蒐集6類運動數據,根據人體姿態能獲得所有關節之三軸位置數據。

行動者評論家網路以人體與機器人兩端之間的潛在向量作學習,人機兩端數據預先訓練變分自動編碼器網路(Variational Autoencoder, VAE),即可獲得兩端之間的潛在向量。
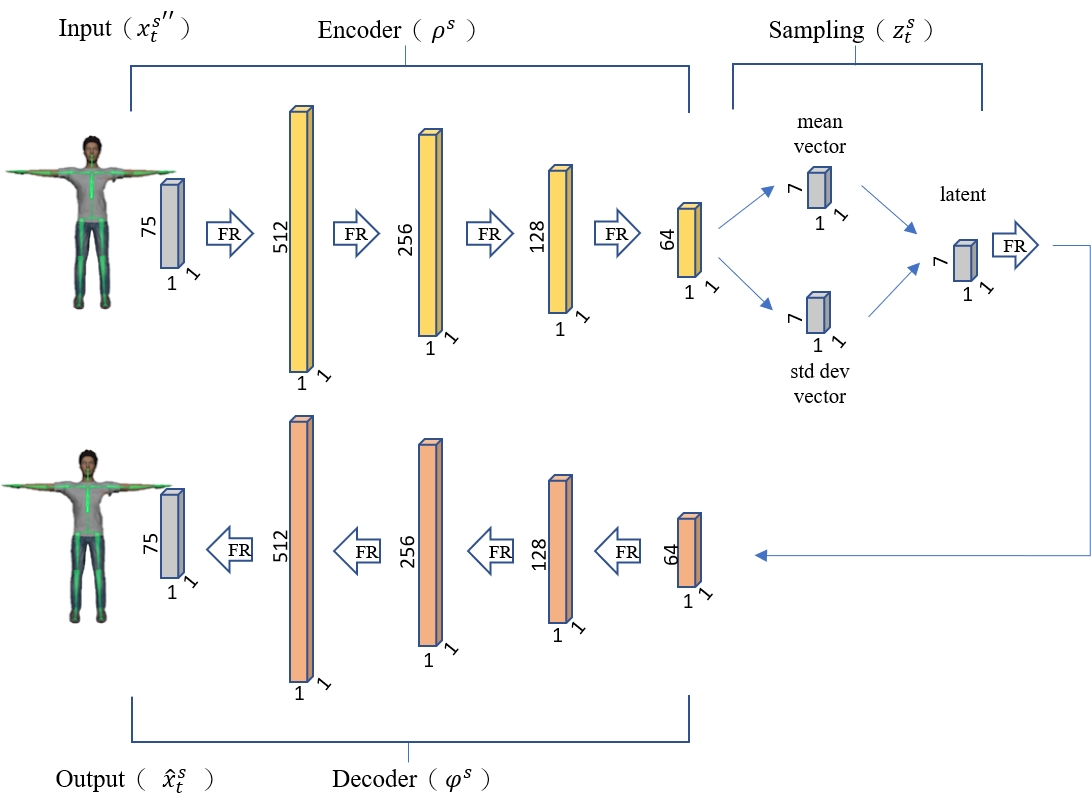
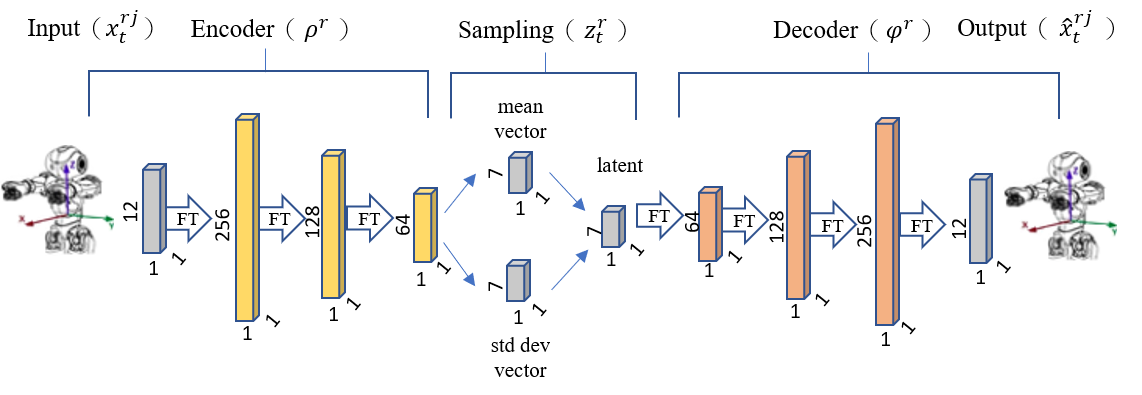
行動者-評論家網路架構,定義智能體之學習策略,模型前饋階段經前處理之骨骼數據會進行編碼,行動者網路將接收骨骼之隱藏含量並自動生成機器人之隱藏含量。
V-REP軟體為智能體與環境的接口,將解碼後的機器人動作於模擬器中實現,模擬器將輸出機器人關節角度與位置
- 位置: 計算手部向量相似度作為模型獎勵機制
- 角度: 角度編碼後的隱藏含量與人體隱藏含量用於模型反饋階段,透過評論家網路給予評級優化行動者網路
- 智能體將比較當前策略與新策略,改進行動者網路以採取更好的行動。
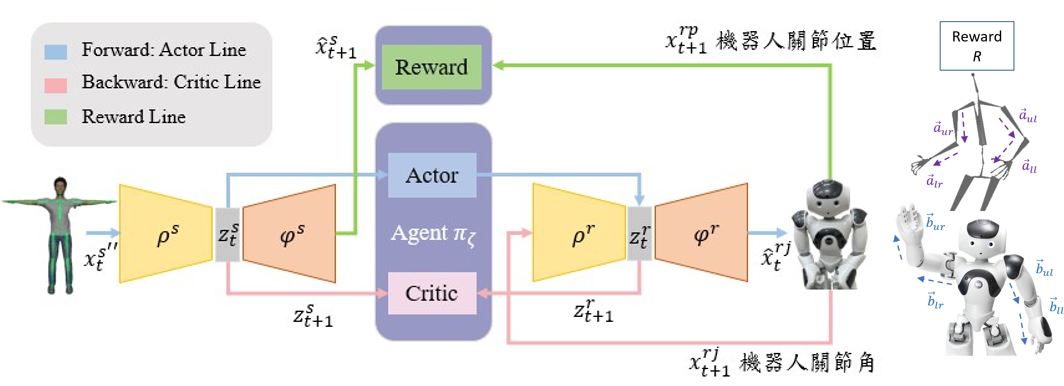
模型目標成功讓智能體學習正確策略,並讓期望的折扣獎勵最大化,模型訓練完畢後人體姿態數據將透過行動者網路生成正確之機器人隱藏含量,並對隱藏含量解碼以得到正確之關節輸出角度。
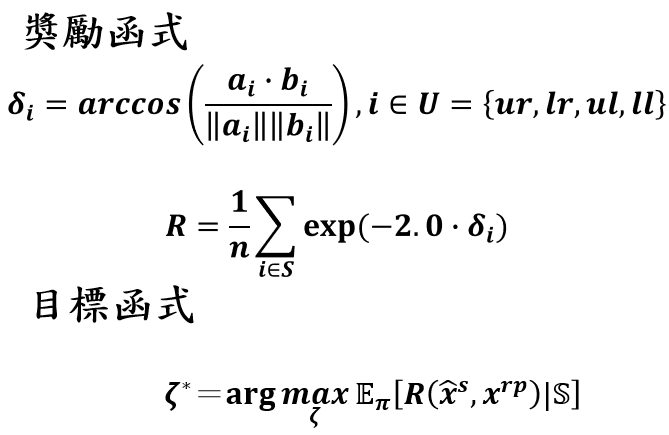
足部控制
依照動畫中左大腿y軸旋轉角與右大腿z軸旋轉角來觸發足部行動。
- 前進: 角度上升 當上升超越40度觸發
- 側移: 角度下降 當下降超越15度觸發
- 轉身: 將動畫面向方位與機器人面向方位對齊,當差距超過40度時,進行修正。

音訊控制
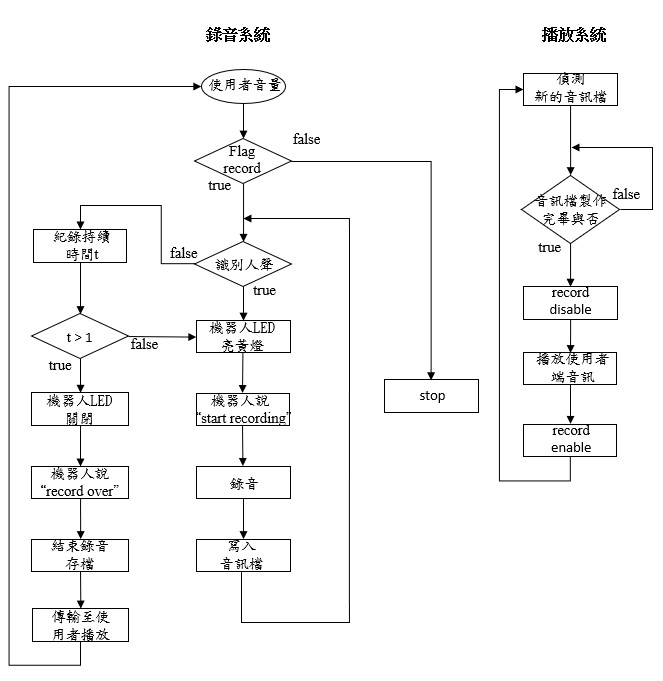
語音系統由錄音系統與播放系統組成,操作者端錄音透過RMS值大小觸發,錄音系統需設定音量閥值,待RMS值大於閥值觸發錄音,由於講話換氣時RMS值會驟降,故限制RMS值小於閥值持續1秒後才中斷錄音,避免斷續錄音的問題,錄完的音檔寫入至兩端共用之雲端硬碟內。
播放系統為播放雲端硬碟中對方儲存之音檔,並持續檢查音訊檔案是否寫入完畢,寫入完畢才能進行播放動作,於兩系統加入條件讓錄音系統與播放系統能順利運行不互相衝突。
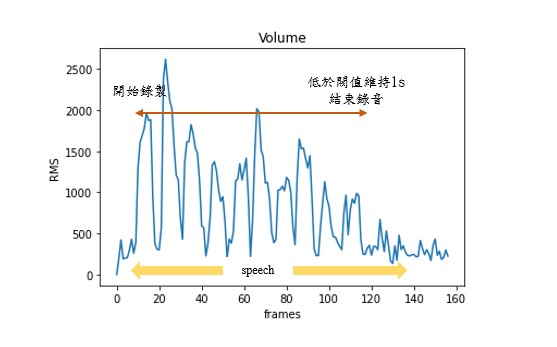
機器人端與操作者端語音系統邏輯設計相同,機器人觸發錄音時會將全身亮起黃色LED燈,並說”start recording”,錄音結束後會將LED熄滅,並說”record over”,以提示機器人端的使用者機器人當前語音系統狀態。
頭部控制
頭部轉向
將Unity與機器人座標軸對齊,並直接給定角度控制機器人頭部轉向。
鏡頭輸出
機器人鏡頭輸出有多種色彩空間與解析度供選擇,本系統將鏡頭設置為RGB色彩空間,因考慮鏡頭畫面流暢度,解析度為320*420,每秒30幀。
透過Wi-Fi連線至機器人鏡頭伺服器,電腦接收機器人視訊畫面後,取出視訊內容之像素點並進行像素點重組,設計超文字標記檔(HTML)之格式內容,將重組後之視訊內容呈現於超文字標記檔中。
視頻流可以在大多數現代瀏覽器(即Firefox、Edge、Chrome 等)中使用,輸入路由器IP與外部連接埠端口即可開啟檔案以檢視機器人視野畫面。
實驗結果
模型訓練
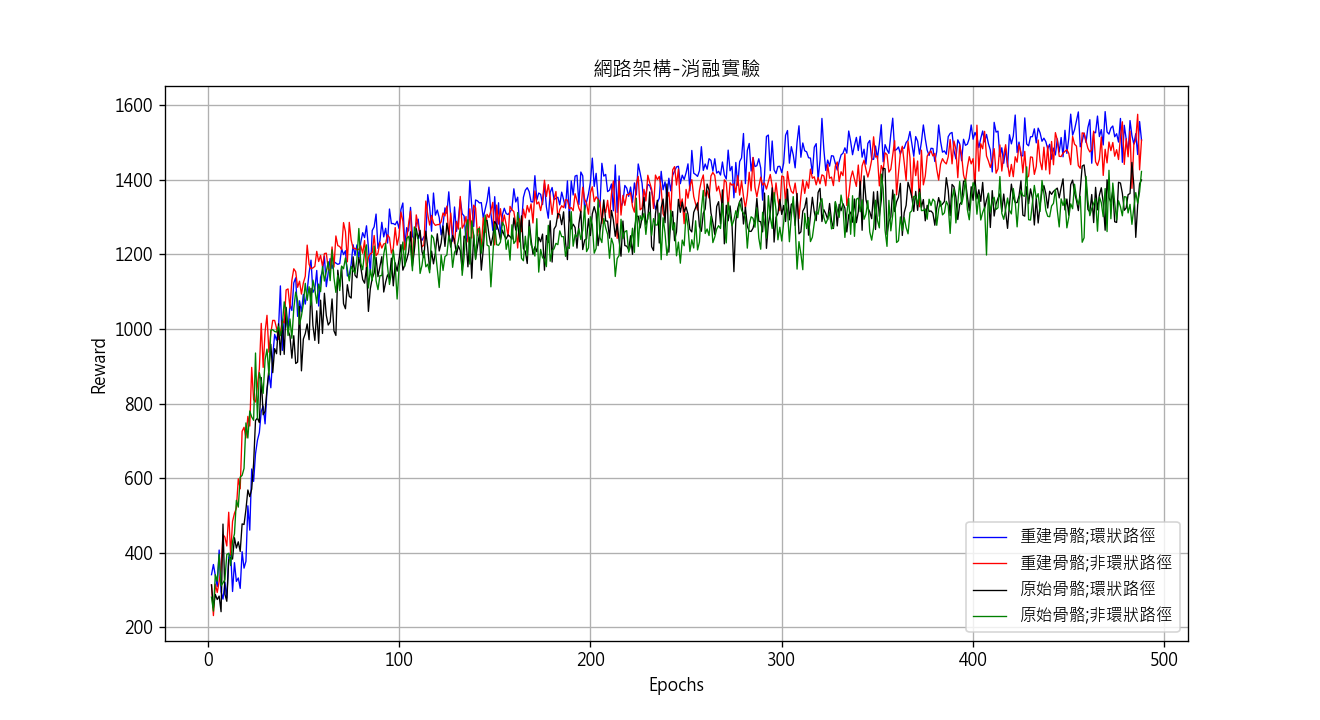
實驗中有4位受試者,共收集720筆人體運動數據,每個目標動作類別分別120筆,將每類別中9成數據用於訓練數據,1成數據用於驗證模型效能,下圖為行動者評論家網路訓練結果圖,模型訓練488個Epoch收斂,於i7-9700與NVIDIA GeForce RTX 2060訓練總時長約26.3小時。
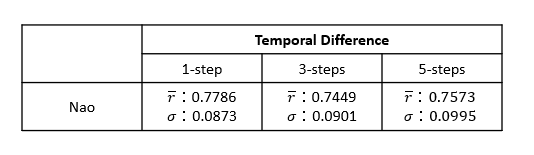
評論家網路透過Temporal Difference (TD) 來計算價值函數,將驗證資料隨機提取5000幀進行模型評估,下表列出不同step TD中模型評估結果,表中分別為平均獎勵與標準差,最終選擇使用1-step TD,因為它性能最佳擁有高平均獎勵與低標準差。
重定向效能評估
已學習動作
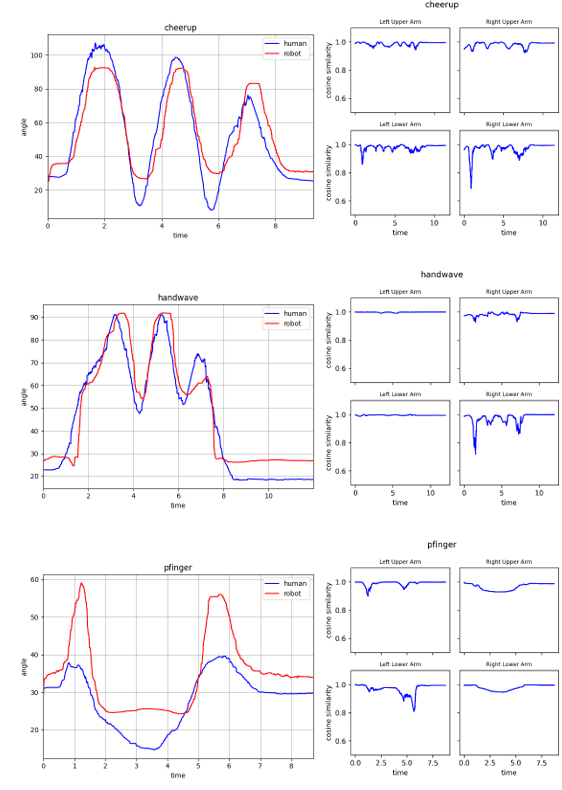
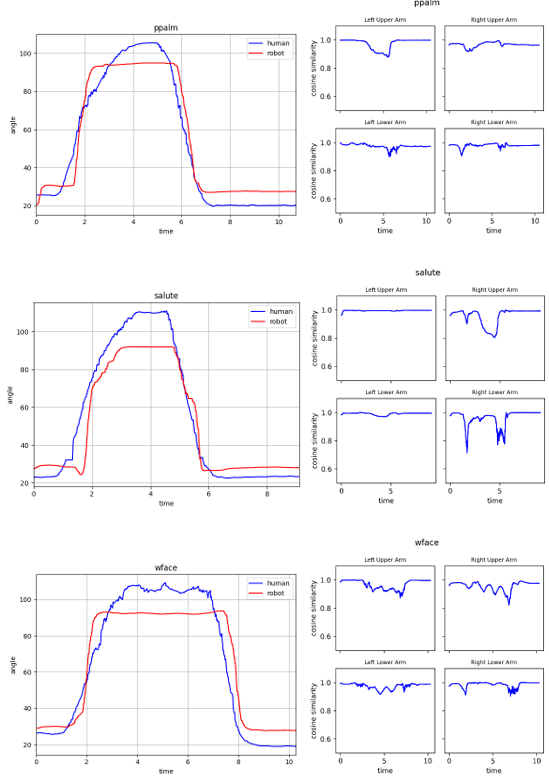
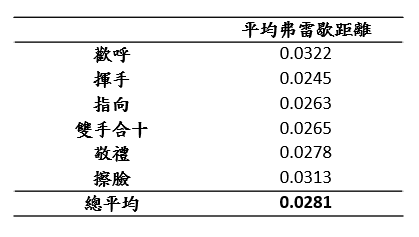
針對6種學習動作歡呼(cheerup)、揮手(handwave)、指向(pfinger)、雙手合十(ppalm)、敬禮(salute)、擦臉(wface)進行效能評估,並使用關節夾角軌跡、餘弦相似度與弗雷歇距離(Fréchet distance)等方式,觀察人機之間運動軌跡的相似度。
圖中左側為關節夾角軌跡圖,右側為手部四個部位之餘弦相似度圖
夾角軌跡圖: 人體與機器人在手部姿態有相同的軌跡趨勢,雙手合十、敬禮與擦臉三動作因硬體限制在動作過程存在角度偏差值。
餘弦相似度: 6個目標動作中四個手部部位的餘弦相似度平均有0.8以上,能達到相當好的重定向效果。
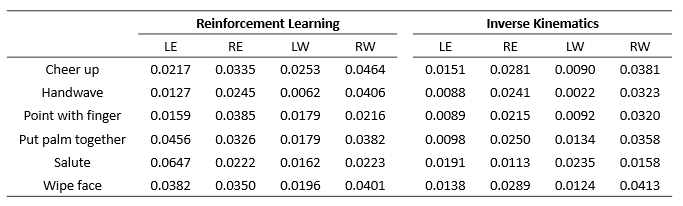
弗雷歇距離(Fréchet distance)為一種路徑空間相似性的描述方式,基於動態規劃思想針對連續性軌跡進行匹配,將匹配距離與採樣方式合併考慮,弗雷歇距離目標求出能夠聯繫兩軌跡之間的最小距離,本研究為人體軌跡與機器人軌跡相比較。
下表為強化學習與逆向運動學兩種方法之弗雷歇距離,單位為公尺,LE、RW、LW、RW分別為左右手肘與手腕,兩種方式之弗雷歇距離大都落在4公分內。
未學習動作
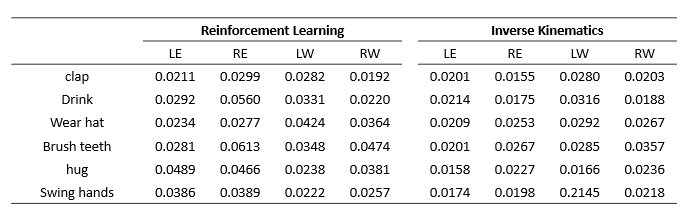
未學習動作的效果能夠測試模型的泛化能力,給定6個未學習的目標動作,擊掌、喝水、戴帽子、刷牙、擁抱、擺手等,透過下表弗雷歇距離可知強化學習在執行這些未學習的動作仍然有很好的表現。
強化學習 vs. 逆向運動學
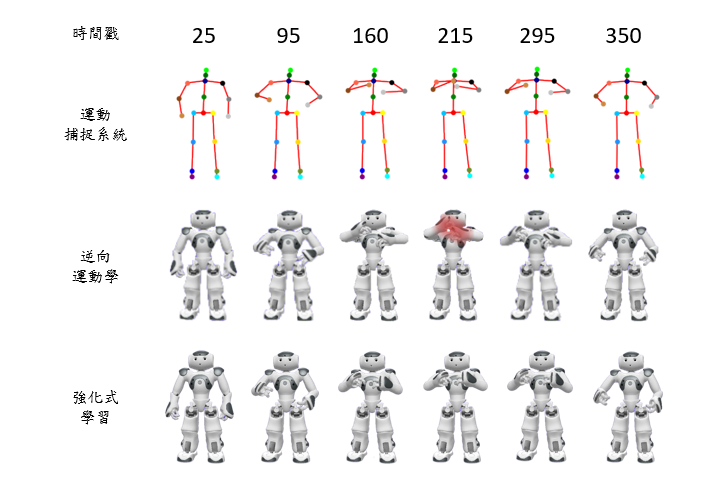
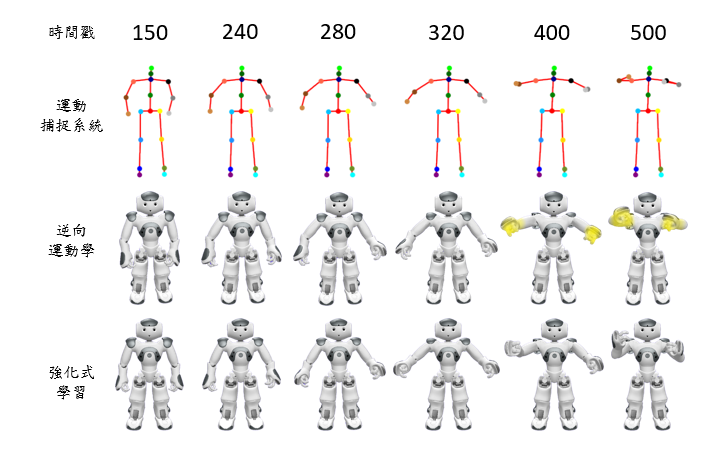
逆向運動學以人體位置為標準依據,透過逆向運動學公式解準確回推機器人關節角度以達到目標位置,然而人與機器人手臂配置不同,因此在做部分動作時機器人會發生自碰撞的現象如下圖紅色區塊處,然而在執行擁抱動作時黃色區塊位置能看出逆向運動學法於手腕處並未呈現出擁抱正確的姿態,故逆向運動學法不適用於真實應用情境中。
強化式學習對於機器人預先編譯動作,資料增強階段加入限定範圍雜訊避免機器人自碰撞現象發生,因此在匹配人體與機器人潛在向量時能夠避免自碰撞現象發生,且能夠根據軌跡經驗做出正確的旋轉角,雖然考慮自碰撞問題會犧牲掉部分準確度,但在容許誤差範圍內此方法適用於與人互動應用情境中。
實際應用場域中,數據經過Wi-Fi遠端傳輸,可能會有網路卡頓與封包掉點等情況發生,逆向運動學僅能依據當下位置推算機器人行為,未能考慮時序資訊,強化式學習法因學習序列的決策,會考慮時序上動作機率的問題,依據軌跡經驗推測行為,在封包掉點的情境中強化式學習法亦為可行方案。
目標學習動作-雙手合十 (自碰撞
未學習動作-擁抱 (關節旋轉不正確
方法分析
| 自碰撞考慮 | 關節旋轉考慮 | 時序資訊 | 應用場景 | 準確度 | |
|---|---|---|---|---|---|
| 強化學習 | O | O | O | 實際與人交互 | 高 |
| 逆向運動學 | X | X | X | 機器人快速動作編譯 | 較高 |
系統評估
要求一位未曾參與過實驗的受試者根據自身習慣執行6個學習的目標動作,其中每個動作做20次,依據強化式學習的方法對機器人手部做運動重定向,對每個動作的20次數據取平均弗雷歇距離,測試手部系統重定向的穩定度,本系統平均軌跡誤差為2.8公分,在重定向控制上具備很高的穩定度。
系統整合應用
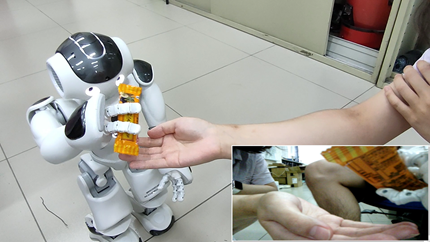
設計一應用場景以結合各個系統的控制,場景內容操作者於甲地穿戴慣性感測器、虛擬實境頭戴式裝置與虛擬實境把手,遠程控制乙地之機器人,透過自身姿態控制機器人與機器人端的用戶打招呼,並向機器人端之用戶A拿取餅乾給用戶B,以達成互動的目標。